Query Processing (Sorgu İşleme)
Query Processing, PostgreSQL’in en karmaşık alt sistemlerinden birisidir. PostgreSQL, SQL standartlarının gerektirdiği çok sayıda özelliği destekler ve sorguları en verimli şekilde işler.
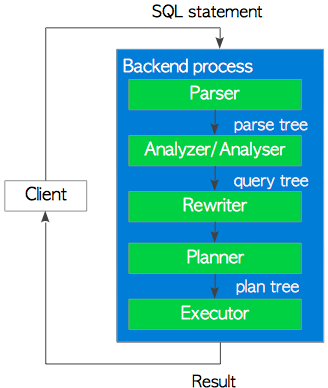
PostgreSQL’de, sürüm 9.6 ile gelen paralel sorgu işleminde birden çok background worker process kullanılıyor olsa da temel olarak bağlı istemci tarafından verilen tüm sorgular bir backend process tarafından işlenir. Backend process; Parser, Analyzer/Analyser, Rewriter, Planner ve Executor olarak beş alt sistemden oluşur.
Parser | Düz metin SQL ifadesinden parse tree oluşturur. |
Analyzer/Analyser | Parse tree’nin anlamsal analizini gerçekleştirir ve bir sorgu ağacı (query tree) oluşturur. |
Rewriter | Varsa rule system’deki kuralları kullanarak sorgu ağacını dönüştürür. |
Planner | Sorgu ağacından en etkin şekilde yürütülebilecek plan ağacını (plan tree) oluşturur. |
Executor | Plan ağacı tarafından oluşturulan sırada, tablo ve indekslere erişerek sorguyu yürütür. |
Parser
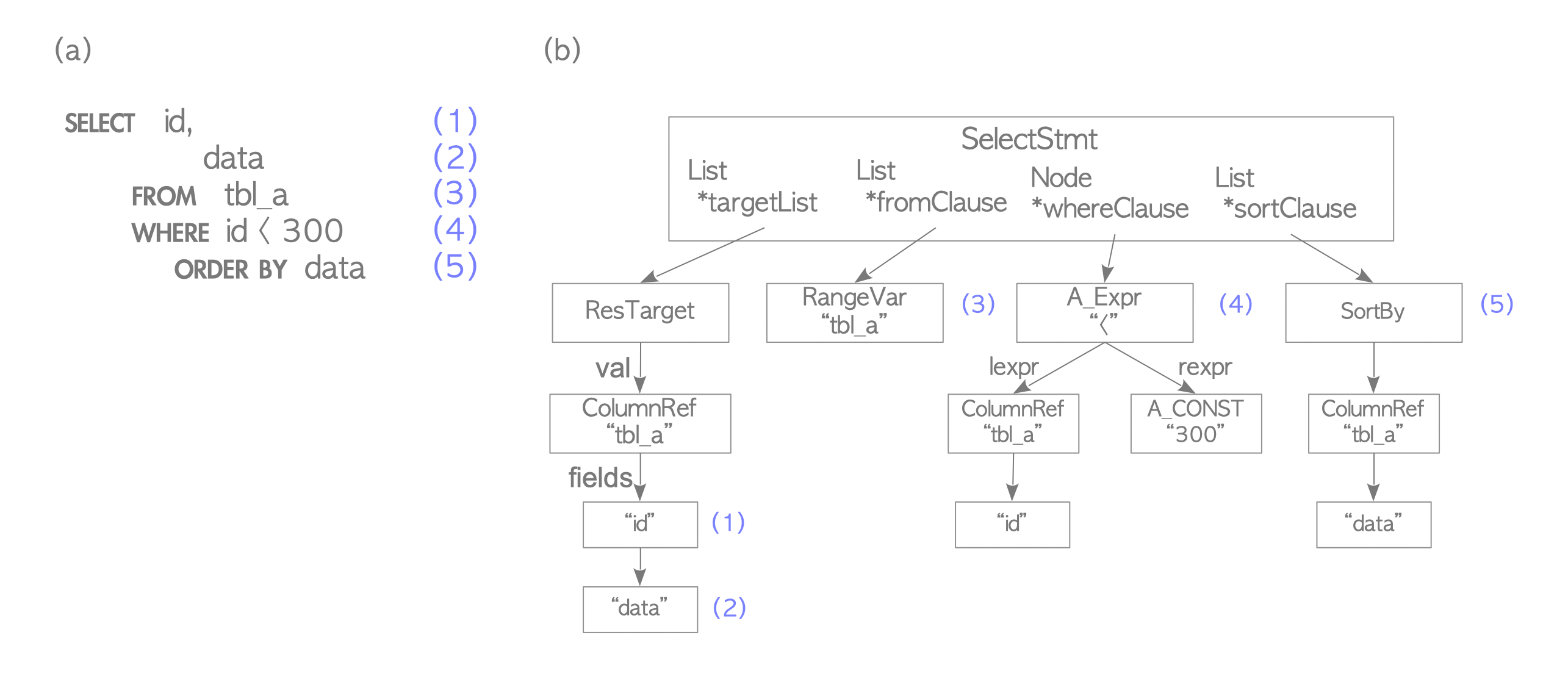
PostgreSQL sunucusu istemciden bir sorgu aldığında sorgu metnini Parser’a teslim eder. Parser gelen SQL ifadesini sonraki alt sistemlerce okunabilir Parse tree’ye (ayrıştırma ağacı) dönüştürür. Örnek ile ele alırsak;
testdb=# SELECT id, data FROM tbl_a WHERE id < 300 ORDER BY data;
Parse tree: parsenodes.h dosyasından tanımlanmış, root düğümü SelectStmt olan bir veri yapısıdır. Şekil 2 (b), (a) örnek sorgunun parse tree’sini ifade eder.
Analyzer
Analyzer, parser tarafından oluşturulan parse tree’nin anlamsal analizini gerçekleştirir ve Query tree oluşturur. Query tree root düğümü parsenodes.h dosyasından tanımlanmış Query structure’ı yapısındadır. Query tree gelen sorgunun metadatasını içerir.
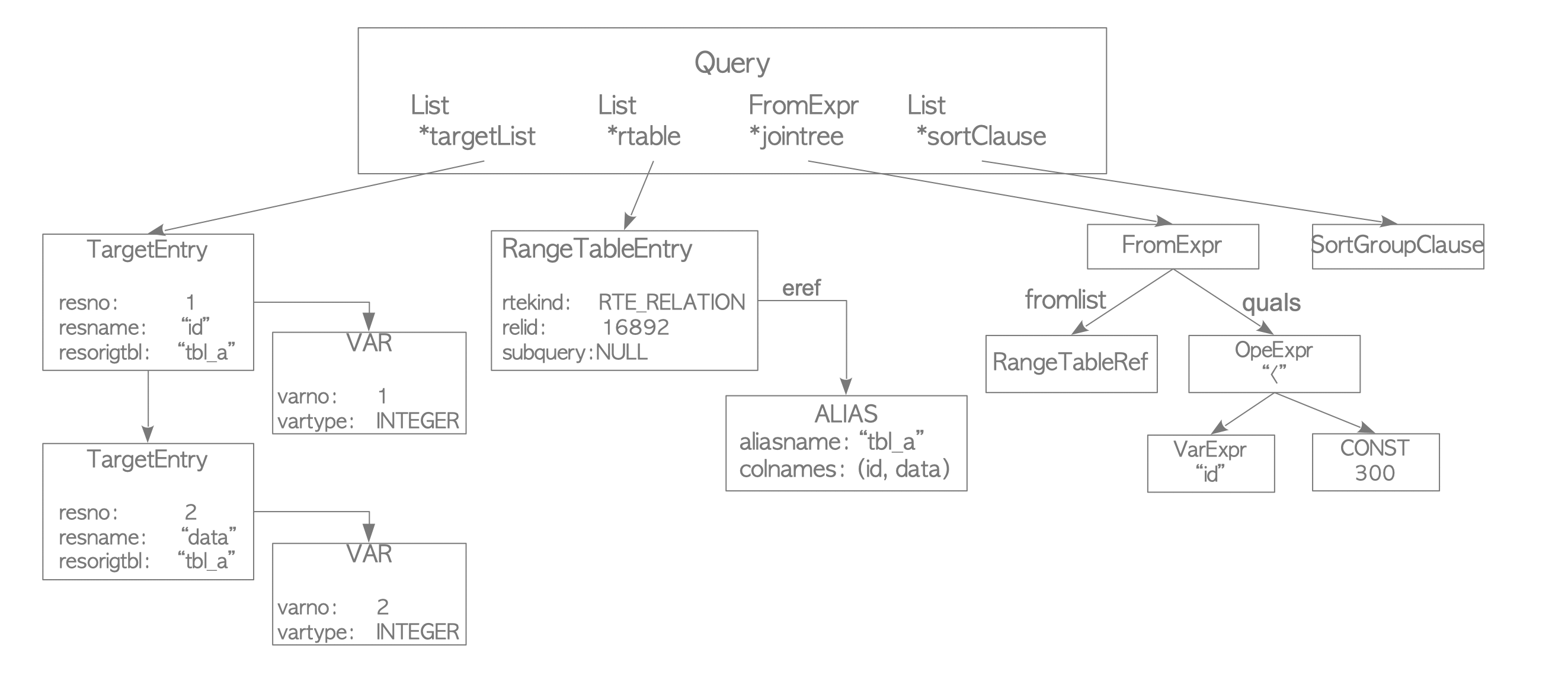
- *targetList, sorguda istenen sütunların listesidir. Örnekte, liste ‘id’ ve ‘data’ sütunları içerir. Gelen query tree
*(asterisk) içeriyorsa analyzer bunu tüm sütunlar için değiştirir. - *rtable (range table), sorguda kullanılan ilişkilerin listesini tutar.
- *jointree FROM ve WHERE yan tümcelerini tutar.
- *sortClause, SortGroupClause öğesinin bir listesidir.
Rewriter
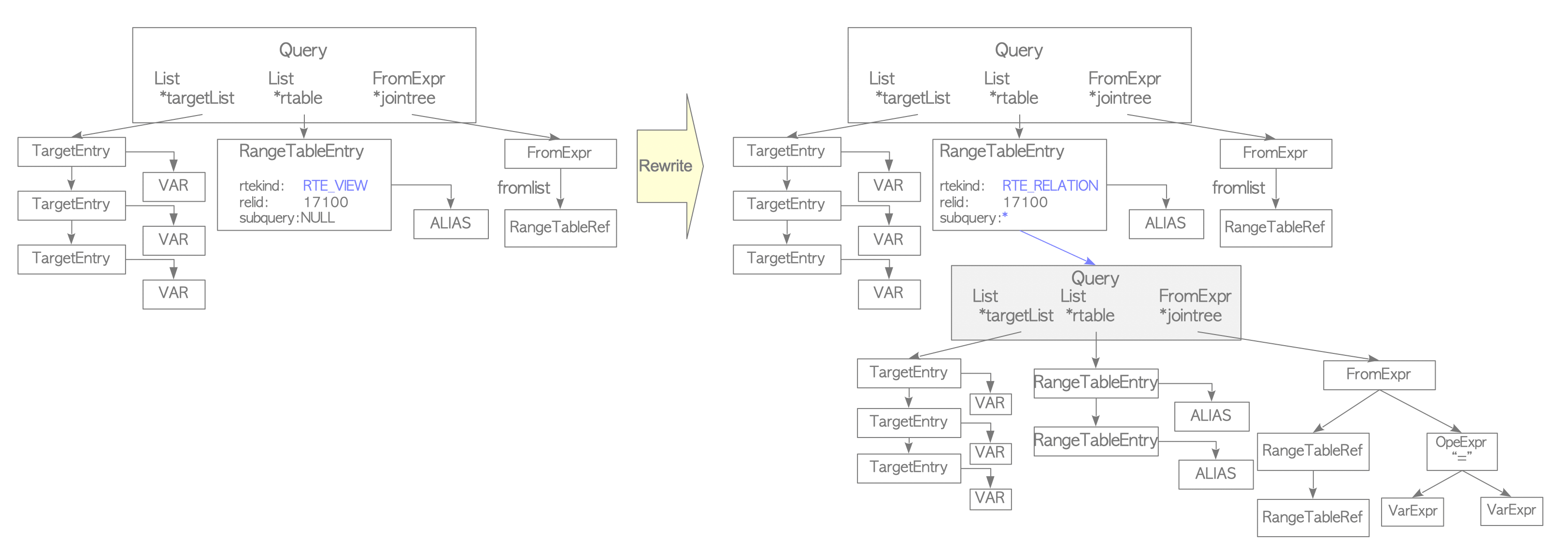
Rewriter, Query tree’yi pg_rules sistem kataloğunda saklanan kurallara göre dönüştüren sistemdir. View’lar bir kural sistemi örneğidir. CREATE VIEW ile bir view tanımlandığında, karşılık gelen kural otomatik olarak oluşturulup katalogta saklanır. Aşağıdaki view’ın önceden tanımlanmış olduğunu ve ilgili kuralın pg_rules sistem kataloğunda depolandığını varsayalım.
sampledb=# CREATE VIEW employees_list AS SELECT e.id, e.name, d.name AS department
FROM employees AS e, departments AS d WHERE e.department_id = d.id;
View’ı içeren bir sorgu verildiğinde, parser Şekil 4(a)’da gösterildiği gibi parse tree’yi oluşturur.
sampledb=# SELECT * FROM employees_list;
Rewriter bu aşamada range table düğümünü alt sorgunun parse tree’si için işler. bu, pg_rules’da karşılık gelen view’dır.
Planner ve Executor
Planner’ın sorumluluğu, query tree’yi taramak ve sorguyu yürütmek için tüm olası planları bulmaktır. Bu adımda rewriter’dan query tree’yi alınır ve executor’ın en verimli şekilde işleyebildiği bir plan tree oluşturulur. Üretilen plan sequential scan veya yararlı bir indeks tanımlıysa index scan içerebilir. Sorgu iki veya daha fazla tablo içeriyorsa, planner tablolara joinlemek için birkaç farklı yöntem önerebilir. Diğer RDBMS’lerde olduğu gibi EXPLAIN komutu ile planner’ın bir sorguyu yürütmeye nasıl karar verdiği görülebilir.
testdb=# EXPLAIN SELECT * FROM tbl_a WHERE id < 300 ORDER BY data;
QUERY PLAN
---------------------------------------------------------------
Sort (cost=182.34..183.09 rows=300 width=8)
Sort Key: data
-> Seq Scan on tbl_a (cost=0.00..170.00 rows=300 width=8)
Filter: (id < 300)
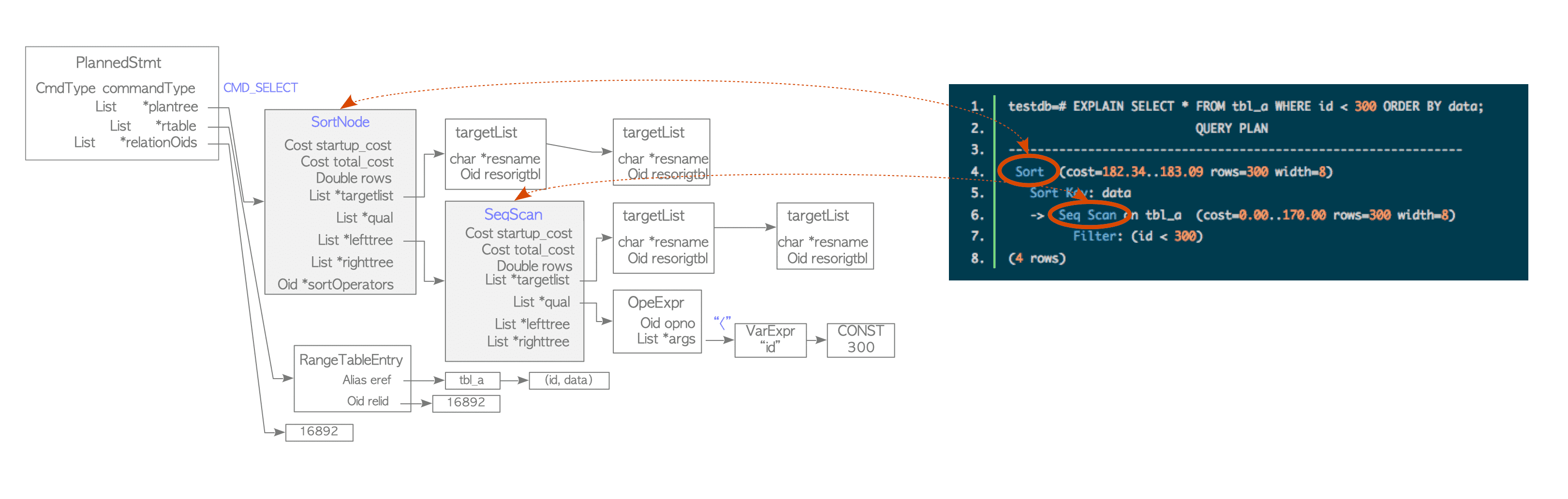
Her plan düğümü, executor’ın işlemek için ihtiyaç duyduğu bilgilere sahiptir. Executor tek tablo sorgularında plan tree’nin sonundan root düğümüne doğru işler. Örneğin, Şekil 5’te verilen plan tree, sort düğümü ve sequential scan düğümünden oluşan bir listedir. Executor tabloyu önce sıralı olarak tarar ve elde edilen sonuçları sıralar.
![Şekil 6. Executor, buffer manager ve geçici dosyalar arasındaki ilişki. [http://www.interdb.jp/pg/img/fig-3-06.png]](/pg-yonetici/images/Query-Processing-1.6.png)
Executor, Buffer Manager aracılığıyla küme içerisindeki tablo ve indeksler üzerinde okuma yazma işlemleri yapar. Sorgular işlenirken executor, önceden ayrılmış temp_buffers ve work_mem bellek alanlarını kullanır, gerekli durumlarda geçici dosyalar oluşturabilir. Ayrıca, PostgreSQL tuple’lara erişirken, çalışan transaction’ların tutarlılığı ve izolasyonu için concurrency control mekanizmasını kullanır.
Kaynak:
[1]. The Internals of PostgreSQL
[2]. Understanding How PostgreSQL Executes a Query