Foreign Data Wrappers (FDW)
Yabancı veri sarmalayıcıları (FDW), kullanıcının veritabanı dışındaki harici veri kaynaklarına yerel veritabanındaki bir tabloymuş gibi sorgular atmasını sağlar. Postgres ve SQL standartlarına uygun diğer ilişkisel veritabanları (MySQL, Oracle, mongoDB), key/value (NoSQL) kaynaklar, flat file veritabanları gibi harici veri kaynaklarına erişimi sağlayan pek çok FDW vardır. FDW’ler PostgreSQL üzerinde bir extension (eklenti) olarak uygulanmaktadır. Geliştirilmiş FDW’lere Postgres wiki üzerinden ulaşabilirsiniz. PostgreSQL Global Development Group tarafından geliştirilen postgres_fdw dışında hemen hemen tüm uzantılar resmi olarak desteklenmemektedir.
Postgres 9.1 sürümünden itibaren bir veritabanı yönetim sisteminin, veritabanı dışında depolanan verileri nasıl entegre edebileceğini tanımlayan SQL Management of External Data (SQL/MED) stardartlarını kullanır. SQL/MED’de, uzak sunucudaki bir tabloya foreign tablo denir. postgres FDW’leri bu tabloları yönetmek için SQL/MED’i kullanır.
PostgreSQL üzerine FDW kurulumu ve daha fazlasına FDW sayfasından ulaşabilirsiniz.
Sırasıyla PostgreSQL ve MySQL üzerinde foreign_pg_tbl ve foreign_my_tbl tablosuna sahip iki uzak sunucu olduğunu varsayalım. Gerekli eklentileri yükledikten ve uygun ayarları yaptıktan sonra, uzak sunuculardaki tablolara tıpkı yereldeki bir tabloymuş gibi sorgular atabilirsiniz. Örneğin, SELECT sorguları ile uzaktaki harici tablolara erişilebilir.
Ayrıca, yerel tablolar ile farklı sunucularda depolanan harici tablolar arasında join işlemleri yapılabilir.
FDW Nasıl Çalışır?
FDW özelliğini kullanmak için uygun eklentiyi kurmanız ve CREATE FOREIGN TABLE, CREATE SERVER ve CREATE USER MAPPING gibi kurulum komutlarını çalıştırmanız gerekir. Gerekli ayarlamalar yapıldıktan sonra sorgular işlenirken foreign tabloya erişmek için uzantıda tanımlanan fonksiyonlar çağrılır.
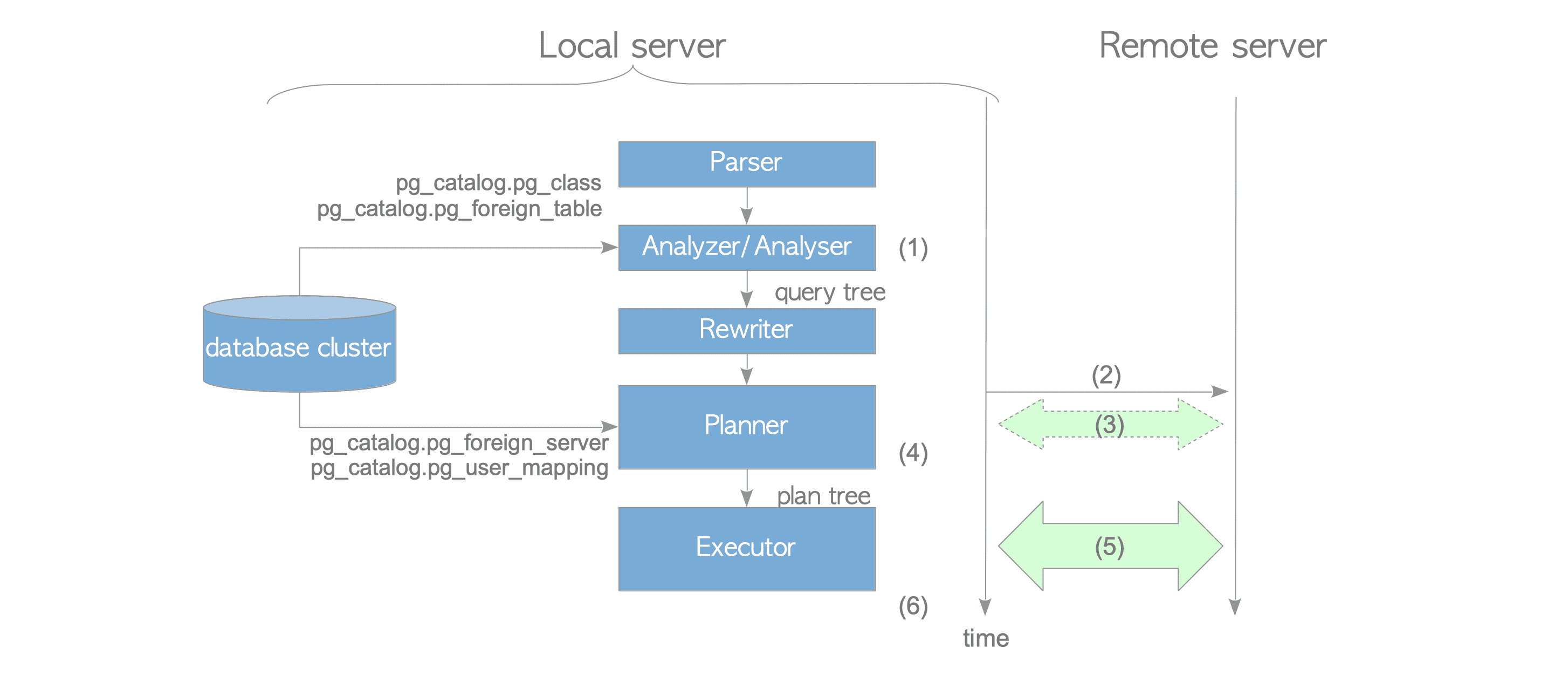
- (1) Analyzer/Analyser gelen SQL’den query tree (sorgu ağacı) oluşturur.
- (2) Planner (ya da executor) uzak sunucuya bağlanır.
- (3) Eğer use_remote_estimate seçeneği açıksa (varsayılan kapalıdır) planner her bir plan yolu maliyeti tahmini için EXPLAIN komutu çalıştırır.
- (4) Planner, plan ağacından düz metin SQL ifadesi oluştur. Bu işleme
deparsingdenir. - (5) Executor düz metin SQL ifadesini uzak sunucuya gönderir ve dönen sonucu alır.
Bir FDW’nin çalışma prensibi temel olarak bu şekildedir. Tüm bu adımlardan sonra executor duruma göre alınan verileri yerel sunucuda işler. Örneğin, çok tablolu bir sorgu yürütülürken executor alınan verileri diğer tablolar ile joinleme işlemleri gerçekleştirebilir.
Query Tree Oluşturma
Analyzer/Analyser foreign tablo tanımlarını kullanarak gelen SQL’in sorgu ağacını oluşturur. Bu tanımlar pg_catalog.pg_class ve pg_catalog.pg_foreign_table kataloglarında tutulur.
Uzak Sunucuya Bağlanma
Planner (executor) uzak veritabanı sunucusuna bağlanmak için belirli kütüphaneler kullanır. Örneğin, uzak PostgreSQL sunucusuna bağlanırken postgres_fdw libpq kütüphanesini, EnterpriseDB tarafından geliştirilen ve uzak MySQL sunucusuna bağlanırken kullanılan mysql_fdw ise libmysqlclient kütüphanesini kullanır.
Bağlantı için gerekli olan kullanıcı adı, sunucunun IP adresi, port numarası gibi parametreler CREATE USER MAPPING ve CREATE SERVER komutları kullanılarak pg_catalog.pg_user_mapping ve pg_catalog.pg_foreign_server kataloglarında saklanır.
EXPLAIN Komutlarını Kullanarak Plan Ağacı Oluşturma (isteğe bağlı)
Postgres FDW’leri gelen sorgunun plan ağacını tahmini için foreign tabloların istatistik bilgilerinden faydalanabilir.
ALTER SERVER komutuyla use_remote_estimate seçeneği açık olarak ayarlanırsa, planner EXPLAIN komutu ile planların maliyetini uzak sunucuda sorgular. Bu seçeneğin kapalı olduğu durumda, maliyet hasabı yapılırken varsayılan sabit değerler kullanılır. İsteğe bağlı bir özelliktir, aktifleştirmek için:
localdb=# ALTER SERVER remote_server_name OPTIONS (use_remote_estimate 'on');
Deparsing
Planner, plan ağacını oluşturmak için foreign tablonun plan ağacındaki tarama yollarından düz metin SQL ifadesi oluşturur. Örneğin, şekil 3 aşağıdaki SELECT ifadesinin plan ağacını göstermektedir.
localdb=# SELECT * FROM tbl_a AS a WHERE a.id < 10;
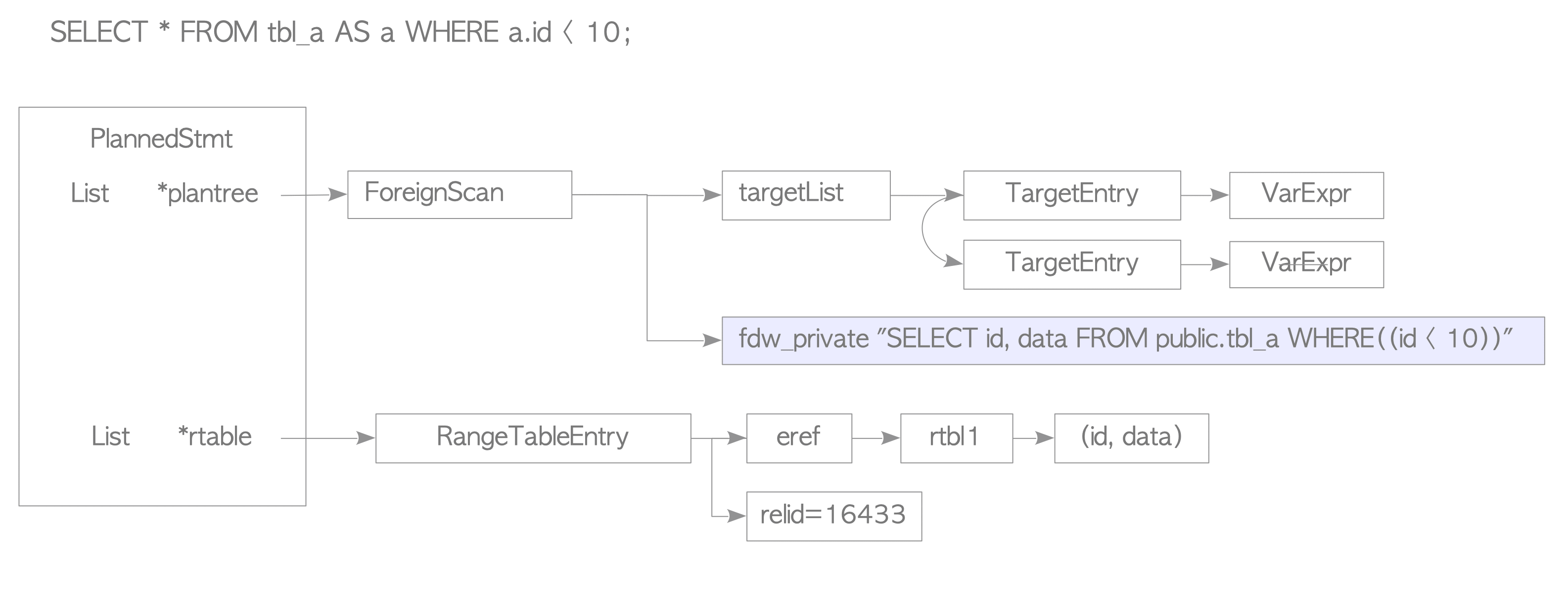
deparsing denir.Aynı şekilde mysql_fdw kullamında MySQL için sorgu ağacından SELECT metni oluşturulur.
SQL İfadeleri Gönderme ve Sonuçları Alma
Deparsing işleminden sonra, executor deparse edilmiş SQL ifadelerini uzak sunucuya gönderir ve sonuçları alır. SQL ifadelerinin uzak sunucuya gönderilme yöntemi her uzantıya göre değişir. Örneğin, mysql_fdw SQL ifadelerini transaction kullanmadan gönderir. mysql_fdw içinde bir SELECT sorgusu çalışırken gerçekleşen SQL komutlarının sırası: (Şekil 4)

- (5–1) SQL_MODE’u ‘ANSI_QUOTES’ olarak ayarla.
- (5–2) Uzak sunucuya bir SELECT ifadesi gönder.
- (5–3) Uzak sunucudan sonuçları al. mysql_fdw, burada sonuçları PostgreSQL tarafından okunabilir verilere dönüştürür. Sonuçları PostgreSQL tarafından okunabilir verilere dönüştürme özelliği tüm FDW uzantıları için ortaktır.
postgres_fdw’de SQL komutlarının sırası biraz daha karmaşıktır. Postgres_fdw içinde bir SELECT sorgusu çalışırken gerçekleşen SQL komutları sırası: (Şekil 5)

- (5–1) Uzak transaction başlat. Varsayılan uzak transaction izolasyon düzeyi REPEATABLE READ.
- (5–2) - (5–4) İmleci bildir. SQL ifadesi temelde bir cursor (imleç) olarak çalıştırılır.
- (5–5) Sonucu almak için FETCH komutunu çalıştır. Varsayılan olarak 100 satır FETCH komutu tarafından getirilir.
- (5–6) Uzak sunucudan sonuçları al.
- (5–7) İmleci kapat.
- (5–8) transaction’ı commit et.
Uzak sunucuda loglar:
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR SELECT id, data FROM public.tbl_a WHERE ((id < 10))
LOG: bind : DECLARE c1 CURSOR FOR SELECT id, data FROM public.tbl_a WHERE ((id < 10))
LOG: execute : DECLARE c1 CURSOR FOR SELECT id, data FROM public.tbl_a WHERE ((id < 10))
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
Postgres_fdw
postgres_fdw eklentisi PostgreSQL Global Development Group tarafından resmi olarak geliştirilen ve kaynak kodu PostgreSQL kaynak kodu ağacında bulunan özel bir modüldür. Postgres 9.3 sürümü ile yayınlanan bu modül gelişimini yeni sürümlerle devam ettirmektedir.
Yukarıda postgres_fdw’nin tek tablolu sorguları nasıl işlediği açıklandı. Bu kısımda ise postgres_fdw’de çok tablolu sorguları, sort operasyonlarını ve aggregate fonksiyonlarını nasıl işlediği açıklanmaktadır. Örnekler SELECT ifadeleriyle verilmiş olsada postgres_fdw’le diğer DML (INSERT, UPDATE ,DELETE) ifadeleride işlenebilir.
Çok Tablolu Sorgular
Çok tablolu bir sorgu çalıştığında postgres_fdw, her bir foreign tabloyu tek tablolu SELECT ifadesi gibi local sunucuya getirir ve join işlemlerini burada yapar. 9.6 sürümü ve sonrasında gelişen postgres_fdw remote join işlemleri yapabilmektedir. Bu özellik foreign tablolar aynı sunucuda ve use_remote_estimate seçeneği açık olduğunda kullanılabilir. Çalışma ayrıntıları aşağıda açıklanmıştır.
PostgreSQL’in iki foreign tabloyu (tbl_a ve tbl_b) joinleyen şu sorguyu nasıl işlediğini inceleyelim:
localdb=# SELECT * FROM tbl_a AS a, tbl_b AS b WHERE a.id = b.id AND a.id < 200;
use_remote_estimate seçeneği açıksa (varsayılan kapalı), postgres_fdw foreign tablolarla ilgili tüm planların maliyetlerini elde etmek için bir dizi EXPLAIN komutu gönderir. Planner tarafından en uygun plan seçilir.
(1) EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((id < 200))
(2) EXPLAIN SELECT id, data FROM public.tbl_b
(3) EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
(4) EXPLAIN SELECT id, data FROM public.tbl_a WHERE ((((SELECT null::integer)::integer) = id)) AND ((id < 200))
(5) EXPLAIN SELECT id, data FROM public.tbl_b ORDER BY id ASC NULLS LAST
(6) EXPLAIN SELECT id, data FROM public.tbl_b WHERE ((((SELECT null::integer)::integer) = id))
(7) EXPLAIN SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2 ON (((r1.id = r2.id)) AND ((r1.id < 200))))
Planner tarafından seçilen planı görmek için localde EXPLAIN komutu çalıştırıldığında, uzak sunucuda işlenen en verimli sorgu olan inner join’i seçtildiği görülür.
postgres_fdw’nin bunu nasıl gerçekleştirdiğine bakalım:

- (3–1) Uzak transaction’ı başlat.
- (3–2) Her bir plan yolunun maliyetini tahmin etmek için EXPLAIN komutlarını göder. Bu örnekte, yedi EXPLAIN komutu gönderilmiş ve planner, yürütülen EXPLAIN komutlarının sonuçlarını kullanarak en verimli olanı seçmiştir.
- (5–1) SELECT ifadesini ifade eden c1 imlecini tanımla.
SELECT r1.id, r1.data, r2.id, r2.data FROM (public.tbl_a r1 INNER JOIN public.tbl_b r2
ON (((r1.id = r2.id)) AND ((r1.id < 200))))
- (5–2) Uzak sunucudan dönen sonuçları al.
- (5–3) c1 imlecini kapat.
- (5–4) transaction’ı commit et.
use_remote_estimate seçeneği kapalıysa (varsayılan böyle), bir romote join sorgusunun nadiren seçildiğini unutmayın çünkü maliyet tahmini çok büyük dahili değerler kullanılarak yapılacaktır.Sort Operasyonları
Postgres sürüm 9.5 öncesinde ORDER BY gibi sıralama operasyonlarında uzak sunucudan tüm hedef satırlar alınıp local sunucuda sıralama işlemi yapılırdı. Bunu ORDER BY ifadesi içeren basit bir sorgu üzerinde EXPLAIN komutuyla gösterecek olursak:
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) sorgusunu uzak sunucuya gönderir ve dönen sonucu alır. 4. satırda ise yerel sunucuda executor getirilen tbl_a satırlarını sıralar.9.6 ve sonraki sürümlerle birlikte postgres_fdw uzak sunucudaki SELECT ifadelerini ORDER BY ile yürütebilir.
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST sorgusunu gönderir ve sıralanmış sonuçları alır. Bu gelişme ile local sunucuda iş yükü azaltılır.uzak sunucudaki loglar:
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: bind : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: execute : DECLARE c1 CURSOR FOR
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) ORDER BY id ASC NULLS LAST
LOG: statement: FETCH 100 FROM c1
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
Aggregate Fonksiyonları
Sürüm 9.6 ve öncesinde, daha önce bahsedilen sıralama işlemine benzer şekilde AVG(), COUNT() gibi aggregate fonsiyonları da local sunucuda aşağıdaki adımlarda yapılırdı.
SELECT id, data FROM public.tbl_a WHERE ((id < 200)) sorgusunu gönderir ve dönen sonucu alır. 4. satırda Executor getirilen tbl_a satırlarının ortalamasını yerel sunucuda hesaplar. Çok sayıda satır göndermek yoğun ağ trafiği tükettiği ve uzun zaman aldığından bu işlem maliyetlidir.Sürüm 10 ve sonrasında postgres_fdw uzak sunucudaki SELECT deyimini ile aggregate fonksununu uzak sunucuda birlikte yürütür.
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200)) sorgusunu gönderir ve dönen sonucu alır. Bu işlem uzak sunucu ortalamayı hesapladığından ve sonuç olarak yalnızca bir satır gönderdiğinden daha verimlidir.Uzak sunucudaki loglar:
LOG: statement: START TRANSACTION ISOLATION LEVEL REPEATABLE READ
LOG: parse : DECLARE c1 CURSOR FOR
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
LOG: bind : DECLARE c1 CURSOR FOR
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
LOG: execute : DECLARE c1 CURSOR FOR
SELECT avg(data) FROM public.tbl_a WHERE ((id < 200))
LOG: statement: FETCH 100 FROM c1
LOG: statement: CLOSE c1
LOG: statement: COMMIT TRANSACTION
Kaynak:
[1]. The Internals of PostgreSQL