Veri Tipleri
PostgreSQL’deki veri tipleri aşağıda sunulmuştur. PostgreSQL’de kullanılabilen veri tiplerinden bazıları PostgreSQL’e özgüdür, diğer veritabanlarında yer almaz. Bazı veri tipleri ise alt türlere bölünerek farklı kullanım alanlarına uyum sağlamayı kolaylaştırarak performans getirileri sunar. Veri tipleri ve alt türleri bu bölümde incelenecektir.
| Veri Tipi | Veri Tipi | Veri Tipi | Veri Tipi |
|---|---|---|---|
| bigint | box | circle | lseg |
| bigserial | bytea | date | line |
| bit [ (n) ] | character [ (n) ] | double precision | jsonb |
| bit varying [ (n) ] | character varying [ (n) ] | inet | json |
| boolean | cidr | integer | interval [ fields ] [ (p) ] |
| macaddr | macaddr8 | money | numeric [ (p, s) ] |
| path | pg_lsn | point | polygon |
| real | smallint | smallserial | serial |
| text | time [ (p) ] | time [ (p) ] w/t TZ | timestamp [ (p) ] |
| timestamp [ (p) ] w/t TZ | tsquery | tsvector | txid_snapshot |
| uuid | xml |
Sayısal Veri Tipleri
- Sayısal veri tipleri, tam ya da rasyonel sayılar gibi farklı büyüklükte (magnitude) ve hassasiyette (precision) veri türlerini saklamaya yararlar.
- Sayısal veri tiplerini tam sayı, virgül sonrası hassasiyeti sabit veya değişken rasyonel sayılar ile seri tipindeki sayılar olarak sınıflandırabiliriz. Bu veri tiplerinde saklanan sayılar virgüllü ya da tam sayı şeklinde, virgülden sonraki hassasiyetine karar verebildiğimiz, negatif ya da pozitif sayılar olabileceği gibi, indeks kolonlarında kullanabileceğimiz otomatik artış verebileceğimiz seri tipinde de olabilir.
- Tam sayı türündeki veri tipleri smallint, integer ve bigint olarak ayrılmıştır. Bunların birim boyutları farklıdır ve negatif - pozitif tam sayılar uzayında değer alabilecekleri aralıklar değişkenlik gösterir.
| Veri Tipi | Boyut | Tanım | Değer aralığı |
|---|---|---|---|
| smallint (int2) | 2 byte | small-range integer | -32768 ile +32767 aralığındaki tam sayılar |
| integer (int4) | 4 byte | typical choice for intege | -2147483648 ile +2147483647 aralığındaki tam sayılar |
| bigint (int8) | 8 byte | large-range integer | -9223372036854775808 ile +9223372036854775807 aralığındaki tam sayılar |
PostgreSQL’de rasyonel sayıları da saklamak için birkaç veri tipi vardır. Bunları virgülden sonraki hassasiyet seviyesini, veri tipinin tanımlanması aşamasında belirlememize veya serbest bırakmamıza göre sınıflandırabiliriz.
| Veri Tipi | Boyut | Tanım | Değer aralığı |
|---|---|---|---|
| decimal | değişken | Kullanıcı tanımlı hassasiyet, mutlak | Ondalık ayracı öncesinde 131072 haneye kadar sonrasında 16383 haneye kadar |
| numeric | değişken | Kullanıcı tanımlı hassasiyet, mutlak | Ondalık ayracı öncesinde 131072 haneye kadar sonrasında 16383 haneye kadar |
Aşağıdaki şekilde tanımlamalar yapılabilir:
NUMERIC(precision, scale)
NUMERIC(precision)
NUMERIC
Son tanımlamada kolonda azami saklama boyutlarına kadar istenen uzunlukta veri saklanabilir. Yani ondalık ayracının bulunduğu yer değişken olabilir. Örneğin aynı alanda 12.345 ve 1234.5 saklayabilmek gibi. İkinci tanımlamada ondalık toplam hane sayısı es geçilerek sıfır tanımlanmış olmakta yani hane sayısı belirlenmiş tam sayı tanımlanmış olmaktadır. İlkinde ise toplam haneye precision’la ve her değerin içinde olabilecek ondalık hane sayısına scale ile karar verilir. Bu alana düşen sayısal olmayan değerlerin tanımlanabilmesi için NaN (Not a Number: Sayı değil) değeri de kullanılabilir. NaN değeri kullanılarak yapılan tüm işlemler NaN’la sonuçlanır.
| Veri Tipi | Boyut | Tanım | Değer aralığı |
|---|---|---|---|
| real | 4 byte | değişken ondalık hassasiyeti, mutlak değil | 6 ondalık hane |
| double precision | 4 byte | değişken ondalık hassasiyeti, mutlak değil | 15 ondalık hane |
Real ve double veri tipleri, tanımı gereği rasyonel olarak tam olarak ifade edilemeyen bunun yerine değerine en yakınsanmış değer olarak kaydedilebilen sayılar için kullanılır. Bu sebeple kesin hesap gerektiren veri tiplerinde bunlar yerine numeric veri tipinin kullanılması tavsiye edilir. Bununla birlikte bu veri tipinde numeric tipine ilave olarak sonsuzluk değerleri de NaN’la birlikte saklanabilmektedir. Hem real hem double veri tipi “Infinity”, “-Infinity” ve “NaN” değerlerini alabilmektedir.
PostgreSQL, IEEE754 standardı uyumluluğundan dolayı float tipini de desteklemektedir. Buna göre aslında float (1) ve float(24) aralığındaki değerler real’a; float(25) ve float(53) aralığındaki değerler de double’a karşılık gelmektedir.
Sayısal değerlerde round fonksiyonu kullanıldığında yuvarlama işlemine verdikleri tepkiler farklıdır. Aşağıdaki örnekte görüleceği gibi numeric bir kolon yuvarlandığında sıfırdan en uzak tam sayıya (yani yukarı) yuvarlanırken, double türünde bir sayı yuvarlandığında (aşağı veya yukarı olduğuna bakılmaksızın) en yakın çift sayıya yuvarlanır.
Bir kolon eğer ID kolonu olarak kullanılacaksa SERIAL tipinde tanımlanabilir. Bu durumda kolonu integer tanımlayıp bu kolon üzerinde bir SEQUENCE oluşturmakla aynı işlem yapılmış olunur. Yine integer (ya da int4) tipinde olduğu gibi serial tipi de aslında serial4’e denktir. Daha az yer kaplayan serial2 (veya smallserial) ve daha geniş değer aralığında çalışabilen serial8 (veya bigserial) de kullanılabilir.
SELECT x,
round(x::numeric) AS num_round,
round(x::double precision) AS dbl_round
FROM generate_series(-3.5, 3.5, 1) as x;
x | num_round | dbl_round
------+-----------+-----------
-3.5 | -4 | -4
-2.5 | -3 | -2
-1.5 | -2 | -2
-0.5 | -1 | -0
0.5 | 1 | 0
1.5 | 2 | 2
2.5 | 3 | 2
3.5 | 4 | 4
(8 rows)
Bu noktada SEQUENCE’lere değinmek gerekirse, Sequence’ler bir tablodaki kolonun otomatik olarak değer almasını sağlayan nesnelerdir. Sequence’ler içinde yaratıldıkları (veya belirtilirse bir başka) şema tarafından sahiplenilirler. Bir sequence’in ismi kendisiyle aynı şema içindeki diğer sequence’ler, tablolar, indeksler, view’lar ve yabancı tablolar (foreign table) arasında benzersiz olmalıdır.
Bir sequence oluşturulma anında veri türüne de karar verilebilir. Varsayılan olarak bigint olan sequence’ler smallint ve int türlerinde de seçilebilir. Bunun için oluşturma anında data_type parametresine istenen veri türü belirtilir. Ayrıca yine oluşturulma anında sequence’in başlayacağı değer, alabileceği en büyük değer veya artış değeri gibi birkaç parametreye karar verilerek işlevsellik kazandırılabilir. Artış değeri için kullanılan increment değişkeninin negatif bir değer alması halinde sequence azalarak da ilerleyebilir. Ayrıca sequence tanımı sırasında minvalue ve maxvalue verilebiliyor olmasına rağmen başlangıç değerine START sözcüğü kullanılarak spesifik olarak da karar verilebilmektedir.
Örneğin varsayılan özelliklerle bir sequence yaratıp START ile başlangıç değeri verdiğimizde, ilk sequence talebimizde (nextval('serial') ile talep ediyoruz) başlangıç değeri 101’in sonra da bir artarak 102’nin geldiğini görüyoruz.
CREATE SEQUENCE serial START 101;
SELECT nextval('serial');
nextval
---------
101
SELECT nextval('serial');
nextval
---------
102
Bir sequence yaratıldıktan sonra, nextval, currval, lastval ve setval fonksiyonları ile işlerlik kazanabilmektedir. Ayrıca cache özelliği ile sequence üretimi önbelleklenerek hızlı hale de getirilebilir. Cache değişkeninin varsayılan değeri 1 olduğu için her seferinde bir otomatik değer üretimi yapılabilir. Aşağıdaki örnekteki gibi bir tabloya satır eklerken indeks atadığımız ID kolonu için nextval() fonksiyonunu kullanabiliriz.
INSERT INTO distributors VALUES (nextval('serial'), 'nothing');
Metinsel Veri Tipleri
Hem char, hem de varchar metinsel verileri saklamak için kullanılan veri tipleridir. Varchar ve char tanımlanma aşamasında verilen n karakteri saklarken, n’den daha uzun bir metin girişi olduğunda hata döndürerek metni n karaktere kırparlar. Varchar(n) tanımlı bir kolonda kolon uzunluğundan kısa metinler girildiğinde, girilen metin kadar fiziksel yer harcarken, char(n) tanımlı kolonda metnin kalanı boşluk karakteri ile doldurularak n karaktere tamamlanır ve n karakterlik fiziksel yer harcar. Diğer veri tipi olan text için bir karakter sınırı tanımlaması yapılmaz. Değişken boyutlu metinler hata vermeksizin kabul edilebilir.
| Veri Tipi | Tanım |
|---|---|
| character varying(n), varchar(n) | değişken uzunluklu sabit boyutlu |
| character(n), char(n) | sabit uzunluklu, boş alanlar boşlukla doldurulur |
| text | değişken sınırsız uzunluklu |
Yine char(n) için n boyut tanımı yapılmazsa 1 karakter uzunluğunda alınır. Yani char = char(1) olur.
char ve varchar alanlarda tanımlanan boyuttan daha uzun bir string girişi (örneğin insert veya cast ile) olduğunda boyut aşımı hatası alınır ve veri azami boyuta kırpılarak girilir.
CREATE TABLE test1 (a character(4));
INSERT INTO test1 VALUES ('ok');
SELECT a, char_length(a) FROM test1; -- (1)
a | char_length
------+-------------
ok | 2
CREATE TABLE test2 (b varchar(5));
INSERT INTO test2 VALUES ('ok');
INSERT INTO test2 VALUES ('good ');
INSERT INTO test2 VALUES ('too long');
ERROR: value too long for type character varying(5)
INSERT INTO test2 VALUES ('too long'::varchar(5)); -- explicit truncation
SELECT b, char_length(b) FROM test2;
b | char_length
-------+-------------
ok | 2
good | 5
too l | 5
Binary Veri Tipi
Binary tipindeki verileri saklamak için PostgreSQL bytea veri tipini kullanır. Bytea veri tipi input ve output için iki formatı destekler: hex ve escape. Her iki format da daima input olarak kabul edilirken output için varsayılan format hex’tir.
SQL standardı BLOB veya BINARY LARGE OBJECT olarak adlandırılmış farklı bir binary veri formatını tanımlamaktadır. Input formatı bytea’den farklıdır fakat sunulan fonksiyon ve operatörler çoğunlukla aynıdır.
Hex veri formatında binary veriler bit başına 2 hexadecimal hane olarak saklanır ve veri stringinin önünde ‘\x’ ifadesi konularak escape formatından ayırt edilmesi sağlanır. Bu format çoğu uygulama ve protokol tarafından kabul edilen bir format olduğu ve bu sebeple dönüşümü daha hızlı olduğu için kullanımda tercih edilmesi tavsiye edilir.
Escape formatı ise geleneksel PostgreSQL bytea tipi formatıdır. Bu format, binary veri stringini ascii karakter dizisi olarak işlerken ascii olarak temsil edilemeyen karakterler için kaçış karakteri karşılıklarını kullanır. Böylece bu formatta da dönüşüm sağlanabilmiş olur. Ascii olarak ifade edilmeyen octetlere örnek aşağıda verilmiştir.

Burada tırnak ve backslash karakterlerinin kullanımına dikkat edilmelidir.
SET bytea_output = 'escape';
SELECT 'abc \153\154\155 \052\251\124'::bytea;
bytea
----------------
abc klm *\251T
Parasal Veri Tipleri
Parasal bilgileri saklamak için PostgreSQL’de MONEY veri tipi kullanılabilir. Bu veri tipinde geçerli olan para tipi bilgisi ve saklanacak verinin ondalık hassasiyeti veritabanının lc_monetary ayarında belirlenir. Kuruş hassasiyeti de diyebileceğimiz bu değer varsayılan olarak virgül sonrası 2 hanedir.
Bu veri tipini kullanırken dikkatli olunması gereken durumlar, özellikle farklı para birimindeki değerlerin aynı tabloya girilmesi halinde ortaya çıkar. Farklı para birimindeki bir tablo yedeği farklı yerel para birimi ayarına sahip bir veritabanına atılırken ya da veritabanında ayarlanandan farklı para biriminde bir nesneyi çalışılan tabloya yazarken dikkat edilmelidir.
Money türünde kaydedilen veriler farklı veri tiplerine dönüştürülebilir. Bununla birlikte içinde parasal varlıkları kaydettiğimiz başka veri kolonlarının money tipine dönüşümlerinde dikkat edilmelidir.
SELECT '12.34'::float8::numeric::money;
Örneğin yukarıda istenen veri float’tan numeric’e dönüşürken yuvarlama hatalarıyla karşılaşma ihtimalimiz yüksektir. Bunu önlemek için parasal varlıklar float tipinde kolonlarda saklanmamalıdır. Money tipini benzer dönüşüme soktuğumuzda ise böyle bir sorun yaşamayız.
SELECT '52093.89'::money::numeric::float8;
Son olarak money tipinde bir parasal varlıkla yapılan çarpma / bölme işlemleridir. Money tipindeki veriler integer tipinde bir veriye bölündüğünde ondalık kısımdaki veri kaybedilir ve tam sayı sonuç elde edilir. Oysa aynı tam sayının real ya da double karşılığı kullanılırsa kuruş bilgisi kaybedilmeden hesaplama tamamlanır. Yine money cinsinden bir veri money cinsinden başka bir veriye bölünürse sonuç double olarak elde edilir, yani sonuç verimiz artık money cinsinde değildir, numerik bir değere dönüşür. Bunun sebebi para birimlerinin birbirlerini götürmesidir.
Tarih / Zaman Veri Tipleri
PostgreSQL çok geniş bir tarih - zaman veri tipi kütüphanesi sunmaktadır. Bu sayede tarih ve zaman fonksiyonları çok etkin bir şekilde kullanılabilmekte ve birbirine dönüştürülerek çok etkin hesaplamalar yapılabilmektedir. Bu amaçla kullanılan veri tipleri arasında timestamp, time, date ve interval sayılabilir. Aşağıda tabloda bu veri tipleri görülmekte ve alabilecekleri en küçük ve en büyük değerler de gösterilmektedir. Ayrıca zamansal çözünürlük kolonunda seçilen zaman biriminin ondalık hassasiyeti de görünmektedir. Bu değer veri tipi tanımlama aşamasında girilmelidir ve 0 ile 6 arasında değerler alabilir.
| Veri Tipi | Depolama Alanı | Tanım | Asgari Değer | Azami Değer | Zamansal çözünürlük |
|---|---|---|---|---|---|
| timestamp [ (p) ] [ without time zone ] | 8 byte | Tarih ve saat (zaman dilimi bilgisi hariç) | 4713 MÖ | 294276 MS | 1 mikrosaniye / 14 hane |
| timestamp [ (p) ] with time zone | 8 byte | Tarih ve saat (zaman dilimi bilgisi dahil) | 4713 MÖ | 294276 MS | 1 mikrosaniye / 14 hane |
| date | 4 byte | Tarih | 4713 MÖ | 5874897 MS | 1 gün |
| time [ (p) ] [ without time zone ] | 8 byte | Saat (zaman dilimi bilgisi hariç) | 00:00:00 | 24:00:00 | 1 mikrosaniye / 14 hane |
| time [ (p) ] with time zone | 12 byte | Saat (zaman dilimi bilgisi dahil) | 00:00:00 +1459 | 24:00:00-1459 | 1 mikrosaniye / 14 hane |
| interval [ fields ] [ (p) ] | 16 byte | Zaman araligi | -178000000 yıl | 178000000 yıl | 1 mikrosaniye / 14 hane |
Tarih zaman veri tipleri arasında INTERVAL diye özel bir veri tipi vardır. Bu belli bir zamandan ziyade zamansal hesaplamalarda zaman aralığı olarak kullanılabilir ve aşağıdaki listede sunulan zaman aralıklarını saklayabilir.
YEAR
MONTH
DAY
HOUR
MINUTE
SECOND
YEAR TO MONTH
DAY TO HOUR
DAY TO MINUTE
DAY TO SECOND
HOUR TO MINUTE
HOUR TO SECOND
MINUTE TO SECOND
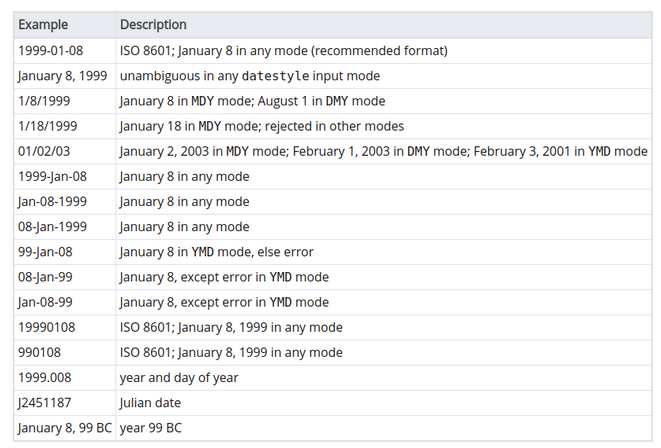
Aşağıdaki tablo tarih tipindeki veriler için bazı örnek gösterimler sunmaktadır.
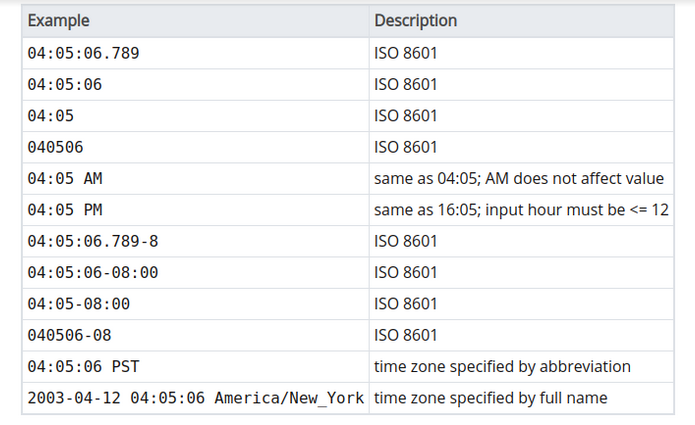
Benzer şekilde aşağıdaki tabloda da saat cinsinden veri tiplerinin gösterimine örnekler verilmiştir.
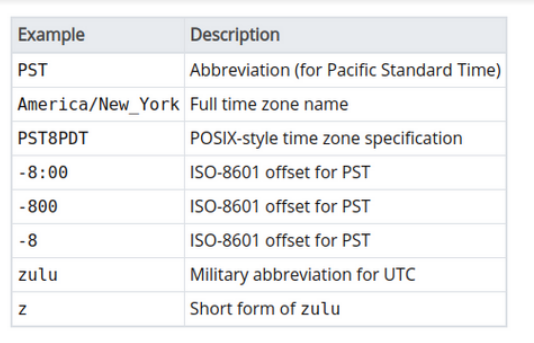
Timestamp with time zone ve time with time zone türündeki veri tipleri zaman dilimi bilgisini de saklamaktadır. Eğer veri tipi “without time zone” şeklinde ise ve girilen veri zaman dilimi bilgisi içeriyorsa, hata verilmez fakat zaman dilimi bilgisi veriden silinir. Zaman dilimi tutan veri türlerinde zaman dilimi bilgisi aşağıdaki şekillerde gösterilebilir.
Timestamp veri tipi tarihi, zamanı ve (istenirse) zaman dilimi bilgisini saklayabilir. Ayrıca timestamp verisinde milattan önceki yıllar için BC, milattan sonraki yıllar için AD ifadesi de saklanabilir. aşağıda timestamp türünde farklı örnekler bulunmaktadır.
1999-01-08 04:05:06
January 8 04:05:06 1999 CET
TIMESTAMP '2004-10-19 10:23:54+02'
Timestamp with time zone türünde bir veri, her zaman tabloda UTC (Universal Coordinated Time) ya da diğer bilinen ismiyle GMT (Greenwich Mean Time) olarak saklanır. Bu sebeple veritabanına giren bir veride açıkça zaman dilimi belirtildiyse bu değer saklanırken UTC’ye çevrilir. Zaman dilimi belirtilmeden girildiyse, varsayılan olarak sistemin zaman dilimi kullanılır ve UTC’ye çevrilerek kaydedilir. Veritabanında bu şekilde kaydedilmiş veriler gösterilirken ise UTC kaydedilmiş bu veriler yerel zaman diliminde gösterilir. Eğer veritabanındaki değerlerin başka bir zaman diliminde gösterilmesi isteniyorsa ya zaman dilimi değiştirilir ya da AT TIME ZONE yapısı kullanılır.
SELECT TIMESTAMP '2001-02-16 20:38:40' AT TIME ZONE 'America/Denver';
Result: 2001-02-16 19:38:40-08
SELECT TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40-05' AT TIME ZONE 'America/Denver';
Result: 2001-02-16 18:38:40
SELECT TIMESTAMP '2001-02-16 20:38:40-05' AT TIME ZONE 'Asia/Tokyo' AT TIME ZONE 'America/Chicago';
Result: 2001-02-16 05:38:40
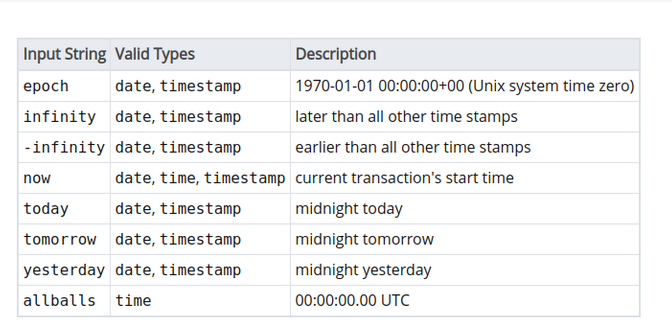
PostgreSQL bünyesinde zamansal anlamda bazı özel ifadeler bulunmaktadır. Bunlar da aşağıdaki tabloda özetlenmiştir. Sistem zamanını almak için ayrıca CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP, LOCALTIME, LOCALTIMESTAMP fonksiyonları da mevcuttur.
Zaman bilgisinin nasıl göründüğü ile ilgili farklı görünüm konvansiyonları vardır. PostgreSQL bu konvansiyonlar arasında geçiş yapabilmek için postgresql.conf içinde bulunan “SET datestyle” komutunu kullanmamıza izin verir. Ayrıca PGDATESTYLE çevre değişkeni de aynı amaçla kullanılabilir. Yine benzer şekilde zaman dilimindeki oturum bazlı değişimler için “SET TIME ZONE” fonksiyonu kullanılabilir.
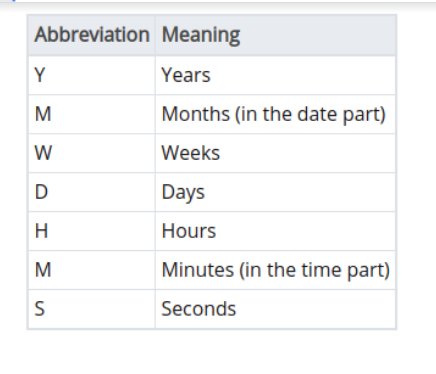
Özellikle tarih saat hesaplamalarında ya da veritabanında yapılacak güncellemelerde kullanmak üzere veya tarihsel farklılıklarının sonucunu sunmak için INTERVAL denilen ve tarih - saat farkı olarak açıklanabilecek bir veri türü de vardır. Bu veri türünde zaman birimi olarak microsecond, millisecond, second, minute, hour, day, week, month, year, decade, century, millennium ile bunların (sonuna s, es veya ies eklenerek yapılmış çoğulları) ya da kısaltmaları kullanılabilir.
Örneğin '1 12:59:10' ve '1 day 12 hours 59 min 10 sec' ifadeleri birbirinin aynısıdır ve herhangi bir tarih - zaman türü veri üzerinde yapılacak işlemlere dahil edilebilir. Aşağıdaki tabloda zamanı veya zaman aralığını ifade ederken kısaltma olarak kullanılabilecek tanımlar bulunmaktadır.
Boolean Veri Tipleri
Boolean veri ihtiyaçları için PostgreSQL’de sunulan BOOLEAN veri tipi TRUE, FALSE ve bilinmeyen durumlarda kullanılmak üzere de NULL değerlerini alabilir. Bu veri tipinde true yerine yes, on, t ya da 1 kabul edilebilirken false yerine de no, off, f ve 0 kabul edilmektedir. Büyük - küçük hassasiyeti aranmaz.
ENUMERATED Veri Tipleri
Sıralı tipler, statik, dizilmiş değerler kümesi olarak ifade edilebilen veri türleridir. Haftanın günleri, yılın ayları ya da kullanıcının tanımlayacağı herhangi bir değerler dizisi tek bir enum veri girdisi olabilir. Bu tür verilerin kullanılabilmesi için kullanıcının ENUM türünde bir veri tanımlaması gerekmektedir. Bu kullanıcı tanımlı tipin hata vermeden kullanılabilmesi için ENUM’da tanımlı haliyle aynı şekilde girilmiş olması gereklidir. Enum içeriği büyük - küçük harfe duyarlıdır ve liste harici elemanları kabul etmez. Ayrıca enum tipindeki veri oluşturulurken tipe giren tüm tanımlamalar, giriş sırasıyla temsil edilen bir liste indeks nosuna sahip olmaktadır. Bu sayede tip içerisinde büyüklük - küçüklük şeklinde bir ilişki de kurularak kullanılabilir.
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');
SELECT * FROM person WHERE current_mood = 'happy';
name | current_mood
------+--------------
Moe | happy
(1 row)
Network Adres Tipleri
PostgreSQL farklı tipte network adreslerinin (IPv4, IPv6, MAC) saklanabilmesini sağlayan veri tiplerinin oluşturulmasına da izin vermektedir. Metin tipinde veriler yerine bunların kullanılması sayesinde hata kontrolü yapmak veya bu veriler üzerinde çalışan bazı özel operatör ve fonksiyonları kullanabilmek mümkün hale gelmektedir.
| Veri Tipi | Boyut | Tanım |
|---|---|---|
| cidr | 7 - 19 byte | IPv4 ve IPv6 ağlar |
| inet | 7 - 19 byte | IPv4 ve IPv6 ağlar / sunucular |
| macaddr | 6 byte | MAC adresleri |
| macaddr8 | 8 byte | MAC adresleri (EUI-64 formatı) |
Network adresi saklarken PostgreSQL’deki seçeneklerimizden ilki inet’tir ve inet tipi ile IPv4 ile IPv6 formatındaki host adreslerini saklayabiliriz. Bu veri tipi alt ağ adresini de opsiyonel olarak saklamaya izin vermektedir. IPv6’da adres boyutu 128 bittir ve 128 bit ile tekil bir sunucu adresi ifade edilir. Eğer ağ adresi saklanırken tekil bilgisayarlar saklanmayıp yerine sadece networkler kabul edilecekse bu durumda inet yerine cidr tipi kullanılması tavsiye edilir.
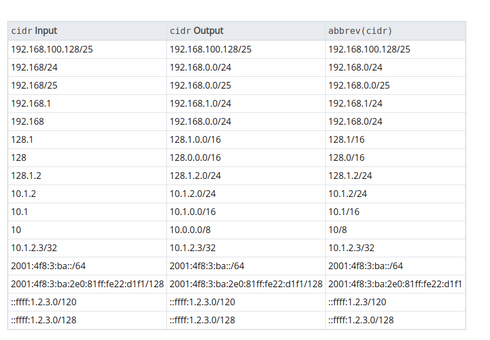
Cidr tipi ise inet’e benzer şekilde IPv4 ve IPv6 network tanımlarını kabul eder. Bununla ilgili örnekler yukarıdaki tabloda verilmiştir. cidr’ın inet’ten temel farkı, cidr tipindeki alana veri girişi yaparken ağ maskesinin sağındaki bitlere sıfır olan değerler kabul edilebilirken inet sadece sıfır olmayan değerleri kabul etmektedir. inet ve cidr tipindeki alanlara girilen verilerin görünümlerini düzenlemek için host, text ve abbrev gibi fonksiyonlar kullanılabilir.
Ayrıca MAC adreslerini saklamak için macaddr ve macaddr8 tiplerinde iki veri tipi daha vardır. macaddr8’in farkı MAC adreslerini EUI-64 formatında saklamasıdır. Aşağıda her ikisi için de kabul edilen örnek gösterimler tabloda sunulmuştur.
| macaddr | macaddr8 |
|---|---|
| ‘08:00:2b:01:02:03’ | ‘08:00:2b:01:02:03:04:05’ |
| ‘08-00-2b-01-02-03’ | ‘08-00-2b-01-02-03-04-05’ |
| ‘08002b:010203’ | ‘08002b:0102030405’ |
| ‘08002b-010203’ | ‘08002b-0102030405’ |
| ‘0800.2b01.0203’ | ‘0800.2b01.0203.0405’ |
| ‘0800-2b01-0203’ | ‘0800-2b01-0203-0405’ |
| ‘08002b010203’ | ‘08002b01:02030405’ |
Metin Arama Veri Tipleri
Bu veri tipi PostgreSQL içinde metin arama (full text search) yapabilme amacıyla bulunmaktadır. Bu modül doğal dil dökümanları koleksiyonu içinde arama yaparak aranan sorguya en yakın ifadeleri getirebilmektedir.
tsvector veri tipi metin arama için optimize edilmiş dökümanı temsil ederken; tsquery veri tipi metin sorgusunu temsil eder.tsvector, dizili kelime sözlüğü olarak adlandırılabilir. tsvector içinde girilen kelimelerde tekrarlanan kelimeler elenir, sıralanır ve her kelime köküne indirgenerek saklanır.
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
Özellikle bir döküman veritabanında ilişkili dökümanların aranıp ilgililik seviyesine göre sıralanarak getirilmesi bu sayede sağlanabilir. Bu veritabanlarında tsvector içinde arama yapılacak metin parçalarını saklamak için kullanılırken araması yapılacak metin parçaları tsquery tipinde bulunur. Bu işlemler metin türündeki verilerin tsvector ve tsquery tiplerine dönüştürülmesi (casting) ile yapılabilir. Bu dönüşüm vasıtasıyla eldeki metinsel verilerde full-text search araması yapılabilir.
Geometrik Veri Tipleri
PostgreSQL, 2 boyutlu geometrik verilerin saklanabilmesi için geometrik veri tiplerine sahiptir. Bu veri tipleri PostGIS veri tipleri ile karıştırılmamalıdır. Zira PostgreSQL bünyesinde çok güçlü bir coğrafi veritabanı modülü olan PostGIS de ayrıca bulunmaktadır. PostGIS, konum bilgisi içeren verilerin saklanmasının ötesinde coğrafi fonksiyonları vasıtasıyla PostgreSQL’de mekansal analizlerin de yapılabilmesini sağlayan ilave yetenekler eklemektedir.
PostGIS’ten ayrı olarak PostgreSQL içindeki geometrik veri tipleri için de aşağıdaki tabloda sunulan tipler mevcuttur.
| Name | Storage Size | Description | Representation |
|---|---|---|---|
| point | 16 byte | düzlemde bir nokta | (x,y) |
| line | 32 byte | sonsuz doğru | {A,B,C} |
| lseg | 32 byte | sonlu doğru parçası | ((x1,y1),(x2,y2)) |
| box | 32 byte | dikdörtgensel kutu | ((x1,y1),(x2,y2)) |
| path | 16+16n byte | kapalı hat (polygon) | ((x1,y1),…) |
| path | 16+16n byte | açık hat (polyline) | [(x1,y1),…] |
| polygon | 40+16n byte | polygon | ((x1,y1),…) |
| circle | 24 byte | çember | <(x,y),r> merkezin koordinatları ve yarıçap |
Diziler
PostgreSQL bir tablonun tipinin dizi olmasına izin vermektedir. Diziler, PostgreSQL’deki herhangi bir dahili ya da kullanıcı tanımlı tipten, enum’dan, kompozit tipten, range veya domain’den oluşturulabilir.
Bir kolonun tipi tanımlanırken köşeli parantezlerle yapılan tanımlamalar dizi oluşturmaktadır. Köşeli parantezlerin içi boş bırakılarak boyutu belirsiz bir dizi, içi doldurularak tanımlı boyutlu diziler oluşturulabilir.
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
CREATE TABLE tictactoe (
squares integer[3][3]
);
Ayrıca SQL standartlarının gerektirdiği ARRAY anahtar kelimesi de değişkenin yanında kullanılarak dizi tanımlanması sağlanabilir. Aşağıda bunlarla ilgili örnekler verilmiştir.
pay_by_quarter integer ARRAY[4],
pay_by_quarter integer ARRAY,
Dizi tipinde veri girişi yapmak için ‘{ deger1 ayrac deger2 ayrac ...}’ formatı uygulanır. Geometrik tipler arasında geçen box tipi hariç tüm tipler için PostgreSQL standardı olarak virgül ayracı kullanılırken box tipinde noktalı virgül kullanılır. Şu örnekte iki boyutlu sabit bir tam sayı dizisi verilmiştir. Dizi 3x3’lük olup pratik olarak dizinin boyut sayısı başlangıçtaki parantez sayısıyla ayırt edilebilir.
ARRAY türünde bir alana veri girişi için aşağıdaki örnekler incelenebilir.
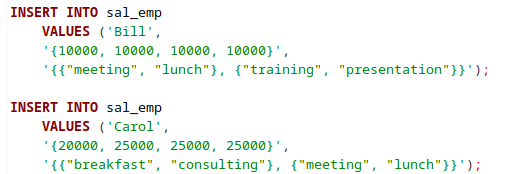
Bunun sonucunda tablo sorgulandığında psql’de aşağıdaki şekilde bir çıktı elde edilir.

Yukarıdaki tabloyu inceleyerek aşağıdaki sorguları çektiğimizde dizi elemanlarına nasıl ulaşıldığını anlayabiliriz.
SELECT pay_by_quarter[3] FROM sal_emp;
pay_by_quarter
----------------
10000
25000
(2 rows)
SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2];
name
-------
Carol
(1 row)
Aşağıdaki UPDATE cümlesi ile dizi içinde bir dilimin değerini güncelleme örneği görülebilir.
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
Dizi elemanları üzerinde PostgreSQL operatörleri kullanılarak çok sayıda operasyon yapmak da mümkündür. Dizi elemanlarına indeks vererek erişme haricinde, diziler birleştirilebilir, içlerinde arama yapılabilir, farklı dizilerin kesişim ya da birleşim kümesi alınabilir. Bunlar için array_prepend, array_append, array_cat, array_dims gibi fonksiyonlar, ||, &&, ANY, ALL gibi operatörler kullanılabilir.
JSON VE XML Veri Tipleri
JSON veri tipleri JSON verileri RFC 7159 konvansiyonuna göre saklayabilmektedir. Bu amaçla kullanacağımız veriyi text olarak da saklayabilecekken, JSON tipinde saklamak hem JSON format kurallarına uygun hale getirir, hem de JSON türüne özel geliştirilmiş çeşitli JSON fonksiyonları da bu veri üzerinde kullanılabilir.
PostgreSQL’de JSON verileri saklayabilmek için json ve jsonb isminde iki veri tipi bulunmaktadır. Bu iki veri tipi neredeyse birbirlerinin birebir aynısı girdileri kabul etmektedir. Fakat aralarındaki en büyük fark verimlilikleridir. JSON veri tipi, girdi verisini aynen saklamaktadır. Bu yüzden JSON işleme fonksiyonları her işlemde veriyi yeniden parçalarına ayrıştırarak (re-parsing) işler. Buna karşın JSONB ise JSON verileri kaydederken parçalarına ayırır ve binary olarak saklar. Bu sebeple verilere fonksiyon uygulanması çok daha hızlı bir hal alır. Bu format kullanıldığında JSON veriler ayrıca indekslenebilir hale gelmektedir.
Çoğu durumda uygulamalar özel gereklilikler yoksa verilerin json yerine jsonb olmasını tercih etmektedir. PostgreSQL, veritabanında sadece bir encoding’e izin vermektedir. Dolayısıyla, veritabanı dil kodlaması UTF8 değilse, JSON tipleri için spesifikasyona katı bir şekilde uymaları mümkün değildir. Bu yüzden json verilerin içine veritabanı encoding ayarına göre izin verilmeyen karakterlerin dahil edilmesi mümkün olmayacaktır. Buna karşın, veritabanı encodingine göre izin verilen fakat UTF8’de olmayan karakterlere ise izin verilmektedir.
Aşağıda izin verilen JSON ifadeler görülebilir.
-- Simple scalar/primitive value
-- Primitive values can be numbers, quoted strings, true, false, or null
SELECT '5'::json;
-- Array of zero or more elements (elements need not be of same type)
SELECT '[1, 2, "foo", null]'::json;
-- Object containing pairs of keys and values
-- Note that object keys must always be quoted strings
SELECT '{"bar": "baz", "balance": 7.77, "active": false}'::json;
-- Arrays and objects can be nested arbitrarily
SELECT '{"foo": [true, "bar"], "tags": {"a": 1, "b": null}}'::json;
Daha önce de bahsedildiği üzere bir JSON değer girilir ve hiçbir işleme tabi tutulmadan ekrana basılırsa json veri tipinde girilen veri aynen basılırken, jsonb türündeki veriler semantik olarak boşluk karakteri gibi önemsiz detayları saklamazlar. Örnek olarak:
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::json;
json
-------------------------------------------------
{"bar": "baz", "balance": 7.77, "active":false}
(1 row)
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::jsonb;
jsonb
--------------------------------------------------
{"bar": "baz", "active": false, "balance": 7.77}
(1 row)
Özellikle bilimsel gösterime sahip üstel sayılarda jsonb’de ortaya çıkan bir davranış da e notasyonunun gizlenerek sayının kısaltılmadan yazılmasıdır. json tipinde ise sayı üstel olarak ifade edilir.
SELECT '{"reading": 1.230e-5}'::json, '{"reading": 1.230e-5}'::jsonb;
json | jsonb
-----------------------+-------------------------
{"reading": 1.230e-5} | {"reading": 0.00001230}
(1 row)
JSONB veri tipinin bir getirisi, bu veri tipindeki kolonlarda GIN indeksi oluşturulabilmektedir. Bu indeks sayesinde hem anahtarlarda, hem de anahtar-değer ikililerinde yüksek performansla arama yapılabilmektedir.
PostgreSQL veritabanları, benzer şekilde, XML türündeki verilerin saklanmasına da izin verir. Bunun için metinsel text türü veriler kullanılabileceği gibi xml veri tipi de kullanılır ve böylece xml dökümanlarının gerektirdiği uyumluluk kontrolü de PostgreSQL tarafından sağlanabilir. Bu veri tipinin getirdiği dahili PostgreSQL fonksiyonları da xml türündeki kayıtlar üzerinde yapılabilecek işlemlerde yardımcı olur.
Metinsel verilerden XML üretmek için XMLPARSE fonksiyonu kullanılabilir.
XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>')
XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>')
PostgreSQL, bunun yerine aşağıdaki yazımı da kabul eder.
xml '<foo>bar</foo>'
'<foo>bar</foo>'::xml
Bunun tersi de mümkündür, PostgreSQL kullanarak XML cümleciğinden metin de üretilebilir. Bunun için XMLSERIALIZE fonksiyonu kullanılır. Çıktının tipi de bu fonksiyon içerisinde belirtilebilir. XMLSERIALIZE kullanarak character, character varying veya text tipinde çıktılar üretmek mümkündür.
XMLSERIALIZE ( { DOCUMENT | CONTENT } value AS type )
RANGE Tipi Veriler
Range tipindeki veriler adından anlaşılabileceği üzere tek değeri değil, bir değer aralığını tutarlar. PostgreSQL’de sayısal ve tarihsel veri tiplerinin range tipleri bulunmaktadır. Örneğin int4range tam sayı aralığını, tsrange ise bir zaman aralığını saklamaya yarar. Bunlara ilave olarak CREATE TYPE fonksiyonu kullanılarak kullanıcı tanımlı range tipleri de oluşturulabilir.
Örneğin tsrange tipinde bir range verisi ‘[2010-01-01 14:30, 2010-01-01 15:30)’ şeklinde yazılabilir. Burada [ ve ] şeklindeki köşeli parantezler dahil, ( ve ) şeklindeki parantezler ise değer hariç anlamına gelir. Yani burada ilk tarihin dahil olduğu fakan son tarihe kadar süren bir zaman aralığı ifade edilmektedir. Range tipi veriler aşağıda sunulmuştur.
int4range: Integer range
int8range: Bigint range
numrange: Numeric range
tsrange: Timestamp without time zone range
tstzrange: Timestamp with time zone range
daterange: Date range
Aşağıda bir otel odası rezervasyonunun tabloya nasıl girildiği, ve bunun üzerinde yapılan işlemler görülebilir.
CREATE TABLE reservation (room int, during tsrange);
INSERT INTO reservation VALUES
(1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
-- Containment
SELECT int4range(10, 20) @> 3;
-- Overlaps
SELECT numrange(11.1, 22.2) && numrange(20.0, 30.0);
-- Extract the upper bound
SELECT upper(int8range(15, 25));
-- Compute the intersection
SELECT int4range(10, 20) * int4range(15, 25);
-- Is the range empty?
SELECT isempty(numrange(1, 5));
Range tipi kolonlar üzerinde GiST ve SP-GiST türünde indeksler oluşturulabilir. Bu tür indeksler özellikle =, &&, <@, @>, <<, >>, -|-, &<, and &> tarzı operatörlerin çok hızlı sonuç döndürmesini sağlar. Bu operatörler sonraki konuda işlenecektir.
DOMAIN Veri Tipleri
Domain tipi başka varolan tiplerin kullanılmasıyla oluşturulan kullanıcı tanımlı bir veri tipidir. Bu veri tipine sahip kolonlarda opsiyonel olarak alabileceği değerleri kısıtlayan CONSTRAINT’ler oluşturulabilir. Bunun haricinde kendisini oluşturan tipler gibi davranacaktır. Bu yüzden domain olarak oluşturulan veri tiplerine uygulanabilecek operatör ve fonksiyonlar da kendisini oluşturan tiplere göre değişecektir.
OBJECT IDENTIFIER (OID) Veri Tipleri
PostgreSQL tarafından sistem tablolarında primary key olarak kullanılan veri tipleridir. Kullanıcı, bir tabloyu oluştururken WITH OIDS ifadesi eklemezse, oluşturulan tabloda OID kolonu bulunmadan yaratılır. Oluşturulan tüm tablolara oid eklenmesi için postgresql.conf’da default_with_oids konfigürasyon değişkeni de aktifleştirilebilir. Aslında OID veri tipi 4 byte’lık bir tam sayıdır (int4). Değer aralıkları küçük olduğu için, büyük veritabanlarında özellikle kullanıcılar tarafından oluşturulmuş tablolarda Primary Key olarak kullanılması önerilmez. OID tipindeki kolonların en yerinde kullanım alanı yine sistem tablolarına referanslar olacaktır.
OID değerleri karşılaştırma için kullanılmalarının ötesinde integer tipine dönüştürülerek çeşitli integer operasyonlarına tabi tutulabilirler. OID, bir satırın object-identifier kolonudur. Eğer bir tablo oluşturulurken WITH OIDS ifadesi eklenirse oluşturulur. Öte yandan postgresql.conf konfigürasyon ayarlarında bu durum için default_with_oids parametresi bulunmaktadır. Bu ayar varsayılan off değerinden on olarak değiştirilirse tüm yeni oluşturulan tablolar WITH OIDS ifadesi girilmeden oid kolonuyla birlikte yaratılır. oid kolonunun veri tipi de oid’dir.
Ayrıca tabloların da kendi içinde kaydında kullanılan tableoid kolonu bulunmaktadır ve yine oid veri tipindedir. TABLEOID değeri, ilgili satırı içeren tablonun oid değeridir. Özellikle inheritance ile oluşturulmuş tablolardan yapılan sorgularda işlevseldir. Bu tür durumlarda bir satırın parent tablosunu söylemek mümkün hale gelir.
Sistem tarafından kullanılan bir başka id tipi de transaction id’si olarak bilinen xid’dir. Her tabloda XID veri tipinde XMIN ve XMAX kolonları bulunur. XID kolonları 32-bit boyutundadır.
xmin: Bir satır üzerinde yapılan her değişiklik (insert, update, delete) o satırın yeni bir versiyonunu yaratır ve bu durumda yeni bir Transaction ID ataması yapılır. XMIN, insert transaction’ı için satırın aldığı kimlik değeridir (transaction id).
xmax: Henüz silinmemiş satırda 0 olan veya silinmiş (DELETE) bir satırda satıra atanan transaction id değeridir.
Üçüncü bir sistem id’si komut id’si (command identifier) olarak bilinen CID‘dir. Bu tipteki kolonlar da CMIN ve CMAX olup aynı XID gibi 32-bit yer kaplar.
cmin: Satır eğer INSERT transaction’ı ile geldiyse komut ID’si (command identifier).
cmax: Satır eğer DELETE transaction’ı ile geldiyse komut ID’si (command identifier).
Son sistem id tipi ise tablo satırları için kullanılan tuple (veya row) identifier yani TID’dir. Bu sistem kolonu olan CTID’nin veri tipidir. Bir TID, blok numarası ve bloktaki satır indeksinden oluşan bir değer çiftidir. TID, bir satırın, tablodaki fiziksel konumunu tanımlamak için kullanılır.
ctid: Bir satırın ctid değeri kullanılarak o satıra hızlıca erişilebilir. Bununla birlikte eğer öncesinde VACUUM FULL işlemi uygulanarak satır güncellendiyse veya taşındıysa CTID değeri de değişecektir. Dolayısıyla CTID kolonu, uzun vadeli bir ID kolonu olarak güvenilir değildir. Bu tür mantıksal bir tespit işinde, OID kolonu hatta daha da iyisi kullanıcının tanımladığı bir seri no kolonu çok daha işlevseldir.
OID kolonlar 32 bit ifadeler olup (uygun önlemler uygulanmazsa) unique değildir. Cluster bazında atanan değerler olan oid kolonlarının değerleri incelendiğinde, uzun zamandır çalışan bir clusterda sarmalama sorunu yaşanabilmektedir. Doğru bir uygulamada, tablodaki satırların versiyon tespit çalışmalarında kullanmak amacıyla bir sequence üretici şiddetle tavsiye edilmektedir. Ya da aşağıdaki önlemleri almak şartıyla OID kullanımı da düşünülebilir:
- Her tablonun OID kolonu üzerinde bir UNIQUE constraint tanımlanmalıdır. Tablonun maksimum satır sayısı (2^32) yaklaşık 4 milyarı (hatta performans sorunları sebebiyle bunun da yarısını) aşmamak kaydıyla bu tür bir çözüm her satır için takip edilebilir unique bir oid değeri üretecektir.
- Eğer veritabanı çapında bir id kolonuna ihtiyaç varsa, tableoid ve oid’nin birleşiminden oluşan bir kolon oluşturulmalıdır.
- Tüm bunların yapılabilmesi için tablolar yukarıda anlatılan şekillerden birisini kullanarak WITH OID seçeneğiyle birlikte yaratılmalıdır.
BIT String Tipi Veriler
Bunlar 0 ve 1’lerden oluşan veri dizileridir. PostgreSQL’de bu tip verileri saklamak için bit(n) ve bit varying (n) kullanılabilir. Burada n değeri pozitif tam sayı olup metinsel verilerdeki gibi veri kolonuna girilebilecek azami dizi uzunluğunu ifade eder.
bit tipinde verinin mutlak olarak n uzunluğunda olması beklenir ve daha kısa metin dizilerinde hata üretir. Bununla birlikte bit varying n uzunluğa kadar herhangi boyutta olabilir. Eğer n değeri girilmezse bit tek karakterlik bit(1) olarak çalışırken bit varying (PostgreSQL alan limitleri ölçüsünde) herhangi bir uzunluktaki bitleri kabul edebilir.
UUID Veri Tipi
Bu veri tipi RFC 4122, ISO/IEC 9834-8:2005 ve bunlarla ilgili standartlara göre tanımlanmış benzersiz tanımlayıcıların (UUID: Universally Unique Identifier) saklanmasında kullanılır. Bu türde saklanan ID’ler 128-bit boyutunda bir algoritma tarafından üretilebilir. Bir UUID, birkaç birimden oluşan, birimleri tirelerle ayrılan 32 küçük hexadecimal karakterden oluşmuş metinsel dizileridir. Aşağıda PostgreSQL tarafından kabul edilen UUID örnekleri görülebilir.
A0EEBC99-9C0B-4EF8-BB6D-6BB9BD380A11
{a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11}
a0eebc999c0b4ef8bb6d6bb9bd380a11
a0ee-bc99-9c0b-4ef8-bb6d-6bb9-bd38-0a11
{a0eebc99-9c0b4ef8-bb6d6bb9-bd380a11}
Kompozit Veri Tipi
Bu veri tipi, var olan birden fazla veri tipinin tek bir veri tipi tanımı altında aynı anda kullanılması gibi düşünülebilir. Bu şekilde tanımlanan kompozit bir veri tipi kendine, bir tablodaki tüm satırın ya da tek bir kolonun temsil edildiği uygulama alanları bulmaktadır.
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
Bu veri tipini kullanan bir tablo oluşturursak,
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
Tek bir kolonda inventory_item türünün içerdiği türleri aynı anda tutabilir ve tek seferde güncelleyebiliriz. Bu satırı sorguladığımızda veya aşağıdaki gibi bir fonksiyon uyguladığımızda sonuçlarını alabiliriz.
CREATE FUNCTION price_extension(inventory_item, integer) RETURNS numeric
AS 'SELECT $1.price * $2' LANGUAGE SQL;
SELECT price_extension(item, 10) FROM on_hand;
Bir kompozit veri türünde türün alt bileşenlerine nokta notasyonunu kullanarak ulaşabiliriz. Aşağıdaki ikisi birebir aynı sonucu döndürür. Tablo isimleri arasında oluşabilecek bir karmaşayı önlemek için ikinci notasyon da kullanılabilir.
SELECT item.name FROM on_hand WHERE item.price > 9.99;
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;